
Introduction
When deploying applications in statefulset in Kubernetes, most workloads are stateless, meaning any pod can be replaced without worrying about its identity or storage. However, certain applications—like databases, messaging queues, and distributed systems—require stable network identities, persistent storage, and ordered deployment/termination. This is where StatefulSet comes in.
What is a StatefulSet in Kubernetes?
A StatefulSet is a Kubernetes workload API object used to manage stateful applications.
It provides:
-
Stable pod names (DNS identities)
-
Persistent storage (via PersistentVolumeClaims)
-
Ordered deployment, scaling, and deletion
Unlike Deployments, where pods are interchangeable, StatefulSets keep track of each pod’s identity.
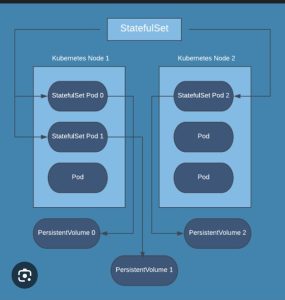
Key Features of StatefulSet in kubernetes
-
Stable Network Identity
Pods are given predictable names like:This ensures each pod is uniquely identifiable.
-
Persistent Storage
Each pod can have its own PersistentVolume that remains even if the pod is deleted. -
Ordered Deployment & Scaling
Pods are created one at a time in a specific order (0 → 1 → 2).
Similarly, deletion happens in reverse order (n → 0). -
Graceful Rolling Updates
Updates occur sequentially, maintaining data consistency.
When to Use a StatefulSet in kubernetes
You should use a StatefulSet when your application:
-
Needs persistent storage for each pod (e.g., MySQL, PostgreSQL, MongoDB).
-
Requires stable DNS names to connect to each pod.
-
Needs ordered scaling (like Zookeeper or Kafka clusters).
-
Must maintain state between restarts.
Examples:
-
Databases: MySQL, PostgreSQL, MongoDB
-
Messaging systems: RabbitMQ, Kafka
-
Distributed systems: Cassandra, Zookeeper, Elasticsearch
StatefulSet vs Deployment
| Feature | StatefulSet | Deployment |
|---|---|---|
| Pod identity | Fixed & predictable | Random |
| Persistent storage | Yes, one per pod | Not guaranteed |
| Deployment order | Ordered | Random |
| Scaling | Sequential | Parallel |
| Use case | Stateful apps (databases, queues) | Stateless apps (web servers, APIs) |
How StatefulSet Works
-
Headless Service
A StatefulSet needs a headless service (clusterIP: None) to manage pod DNS names. -
Persistent Volumes
Each pod gets its ownPersistentVolumeClaim. -
Pod Management Policy
By default, pods are created/deleted one at a time. -
Scaling
Scaling up adds new pods with increasing numbers; scaling down removes pods from the highest number first.
Example
How it works:
-
The headless service ensures each pod gets a DNS name like
nginx-0.nginx-headless.default.svc.cluster.local. -
Each pod gets a persistent volume so that its data remains after restarts.
-
Pods are deployed in order:
nginx-0, thennginx-1, thennginx-2.
Accessing StatefulSet Pods
You can directly connect to each pod using:
Or ping using:
Best Practices for Using StatefulSet in kubernetes
-
Use Proper Storage Classes
Always define aStorageClassthat matches your storage backend. -
Plan Scaling Carefully
Scaling StatefulSets can take time because pods start sequentially. -
Avoid Frequent Restarts
Restarting pods may affect availability. -
Use Readiness Probes
Ensure the pod is ready before allowing traffic. -
Combine with PodDisruptionBudgets
Prevent too many pods from going down during maintenance.
Limitations of StatefulSet in kubernetes
-
Slower scaling compared to Deployments
-
Not suitable for stateless applications
-
Requires careful storage management
Conclusion
A StatefulSet in kubernetes is the ideal solution for running stateful workloads that require persistent storage, stable identities, and ordered deployment.
By understanding its features, use cases, and limitations, you can design Kubernetes clusters that handle critical, stateful applications reliably.
If you are deploying a database, message queue, or distributed service on Kubernetes, mastering StatefulSets is essential for ensuring data integrity and high availability.