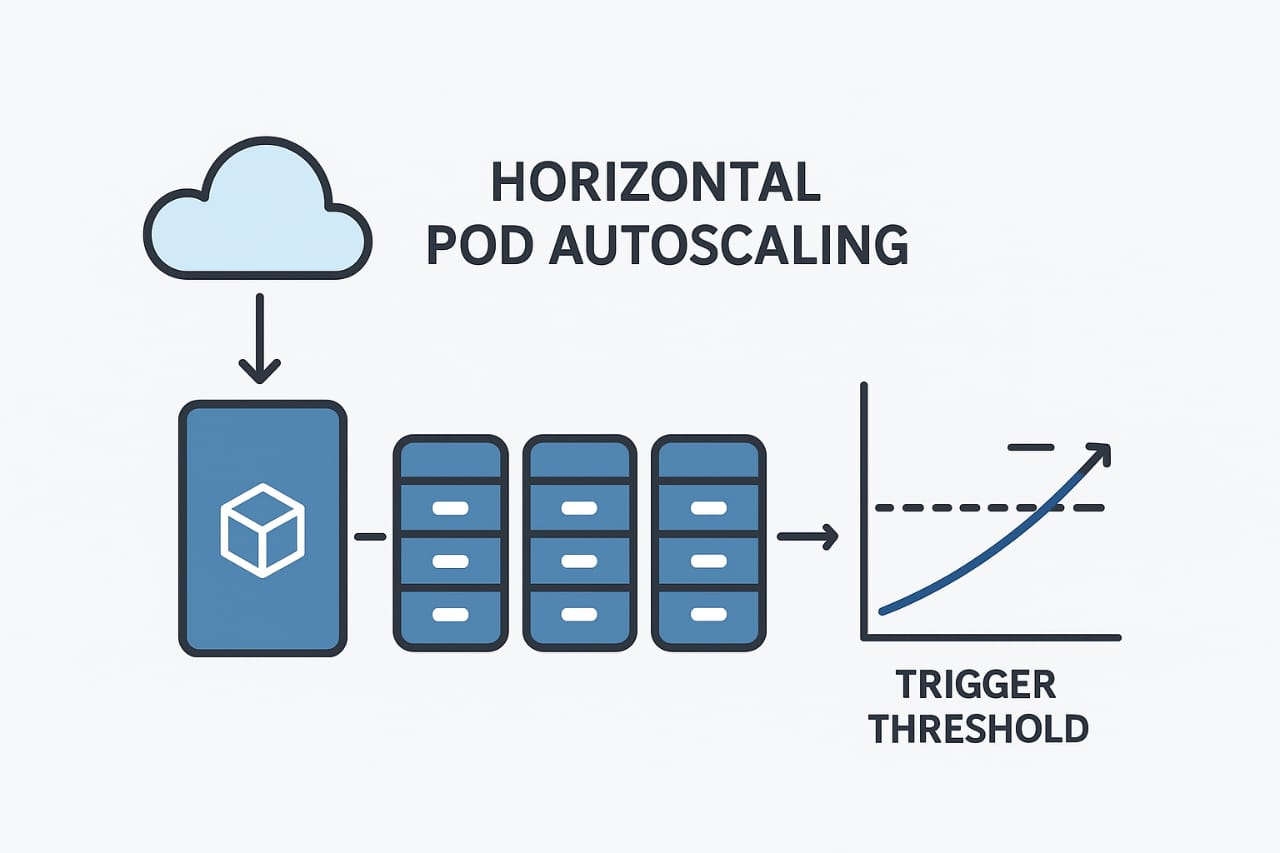
What Is Horizontal Pod Autoscaler in Kubernetes?
Horizontal Pod Autoscaler in Kubernetes, or HPA, is a Kubernetes mechanism that automatically adjusts the number of pod replicas—scaling out when workload increases and in when it decreases—to ensure applications reliably meet demand . Unlike vertical scaling (which increases CPU or memory of existing pods), Horizontal Pod Autoscaler in Kubernetes by modifying the pod count in Deployments, StatefulSets, or similar resources.
It works through a control loop: the HPA controller periodically retrieves metrics (like average CPU utilization) and compares them against user-defined targets. If the average deviates significantly—beyond tolerance thresholds—it adjusts the number of pods
Why Use Horizontal Pod Autoscaler in Kubernetes? Benefits and Use Cases
Horizontal Pod Autoscaler in Kubernetes brings multiple advantages:
-
Automatic Scaling: Frees up DevOps teams from manual resizing, enabling elastic workloads. It adapts to fluctuations—such as sudden traffic spikes—without manual effort .
-
Resource Efficiency and Cost Savings: Avoids overprovisioning and reduces idle resource spending. By scaling in downtime and scaling out under load, you optimize infrastructure usage Segment reported saving over $100,000 per month by tuning HPA correctly.
-
Improved Resilience and Performance: Ensures enough pod replicas are available to handle client requests, maintaining reliability and responsiveness.
-
Environmental Impact: Efficient scaling contributes to reduced energy consumption and lower carbon footprint
-
Flexible Scaling Metrics: While CPU and memory are standard metrics, HPA also supports scaling via custom or external metrics—like request rates, queue lengths, or application-specific counters—provided the appropriate metric APIs are in place.
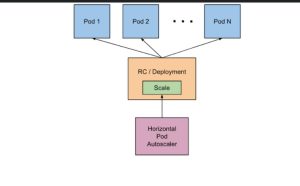
Challenges and Limitations for Horizontal Pod Autoscaler in kubernetes
Even powerful tools like HPA have caveats:
-
Metric Latency: There can be delays between data collection and scaling action—potentially leading to over- or under-scaling in rapidly changing situations.
-
Thrashing: Rapid metric fluctuations may cause frequent scaling up/down actions, leading to instability—especially if pod resource requests aren’t well configured.
-
Incompatibility with VPA: Vertical Pod Autoscaler adjusts resource limits of existing pods. When used alongside HPA, they can interfere with each other—creating unpredictability in scaling behavior.
-
External Factors Blind Spot: HPA only reacts to metrics it knows about—unmonitored external dependencies (e.g., third-party APIs) may still cause performance issues not reflected in CPU/memory data.
-
Workload Type Constraints: HPA only works with scalable workloads (Lists, Deployments, StatefulSets) and doesn’t apply to DaemonSets or jobs.
Advanced Configuration & Custom Metrics
To leverage HPA fully, advanced setups include:
-
Custom Metrics: Using APIs like
custom.metrics.k8s.ioandexternal.metrics.k8s.io, you can drive scaling based on application-specific indicators—like active sessions or queue depth. Tools like Prometheus Adapter or Kube Metrics Adapter help integrate HPA with Prometheus metrics to enable. -
Tuning Sync Intervals: The default HPA sync period is ~15 seconds, but can be customized (via configs like
--horizontal-pod-autoscaler-sync-period) depending on your workload’s responsiveness needs -
Stabilization Windows: Configurable delay windows help prevent rapid successive scaling actions, mitigating thrashing
-
Performance Tuning: GKE users found that raising CPU target from 50% to 70% significantly improved resource efficiency with minimal performance trade-off. Adjusting pod resource requests also impacted autoscaling effectiveness
What’s New: Kubernetes v1.33—Configurable Tolerance
A recent Kubernetes update adds customization to the internal tolerance applied before scaling:
Historically, Horizontal Pod Autoscaler in Kubernetes uses a default 10% tolerance threshold—meaning it only scales when the current metric deviates by more than ±10% from the target . While adequate for small deployments, largescale environments could experience too frequent scaling—or delayed adjustments—due to this coarse threshold.
As of Kubernetes v1.33 (released in April 2025), users can now configure the tolerance level per deployment—allowing fine-grained control over when scaling triggers occur . For example, setting a tighter threshold (e.g., 5%) yields more responsive scaling, while looser thresholds (e.g., 15%) help reduce unnecessary scaling actions. This enhancement boosts both stability and efficiency—especially in large clusters with many replicas.
Horizontal Pod Autoscaler in Kubernetes Configuration Walkthrough
Here’s a simplified step-by-step guide:
-
Ensure Metrics Server Is Deployed
Install via kubectl if not already present: -
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlConfirm deployment:
-
Define Basic HPA
Or explicitly via YAML:
-
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60 -
Monitor HPA Behavior
-
Add Custom Metrics (Optional)
Deploy Prometheus + adapter and configure the HPA to use custom or external metrics. -
Tune Tolerance (v1.33+)
Adjust the threshold for scaling sensitivity. This new alpha feature gives you greater control over scaling frequency and responsiveness .
Conclusion & Best Practices Horizontal Pod Autoscaler in Kubernetes
Horizontal Pod Autoscaler in Kubernetes is a cornerstone of Kubernetes’ elasticity—enabling workloads to self-scale based on real-time demands. It enhances reliability, cost-efficiency, and operational agility. But to extract its full value, consider these best practices:
-
Always set accurate resource requests/limits for your pods.
-
Use custom/external metrics when CPU/memory isn’t a good scaling proxy.
-
Tune CPU/target utilization based on performance and cost balance—as small changes can yield significant savings.
-
Utilize stabilization and tolerance settings to prevent unnecessary scaling turbulence.
-
Leverage features from newer Kubernetes versions—like the configurable tolerance in v1.33—to fine-tune scaling behavior to your use case.
You can also explore the [Prometheus Adapter](https://github.com/kubernetes-sigs/prometheus-adapter)
for integrating custom metrics with HPA.