1. Why Operating System Upgrades Matter in Kubernetes
Operating System Upgrades in Kubernetes Clusters node runs an operating system — usually Linux distributions like Ubuntu, CentOS, Debian, or Red Hat Enterprise Linux. This OS underpins the container runtime, kebeles, and other essential components. It was critical for security, performance, and compliance. In this guide
Upgrading the OS brings benefits such as:
-
Security patches: Fix vulnerabilities in the Linux kernel, system libraries, and networking stack.
-
Performance improvements: Better resource scheduling, filesystem enhancements, and networking optimizations.
-
Compatibility: New Kubernetes releases may require updated OS packages or kernel versions.
-
Bug fixes: Eliminate stability issues that could cause node crashes or degraded performance.
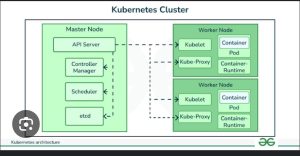
2. Risks of Skipping OS Upgrades
Operating System Upgrades in Kubernetes Clusters Kubernetes environments:
-
Unpatched vulnerabilities — Attackers can exploit known flaws to compromise nodes.
-
Outdated dependencies — Older kernels may lack support for modern Kubernetes features.
-
Incompatibility — New CNI plugins, CSI drivers, or Kubernetes components may fail on outdated OS versions.
-
Reduced vendor support — Cloud providers and Linux vendors may stop providing patches.
3. OS Upgrade Strategies in Kubernetes Clusters
Operating System Upgrades in Kubernetes Clusters unlike traditional servers, Kubernetes nodes are part of a cluster — meaning OS upgrades require careful coordination to avoid downtime.
a. Rolling Node Replacement
-
Create a new node with the updated OS image.
-
Drain workloads from an old node.
-
Delete the old node and join the new one to the cluster.
-
Repeat for all nodes.
Pros: Minimal disruption, safer for production
Cons: Requires node provisioning automation (e.g., Terraform, Ansible, cloud templates)
b. In-Place OS Upgrade
-
Upgrade the OS on the existing node using package managers like
aptoryum. -
Reboot to apply changes.
-
Restart kubelet and other services.
Pros: Simpler for small clusters
Cons: Higher risk — if something goes wrong, the node may fail to rejoin
c. Immutable Infrastructure Approach
-
Destroy old nodes entirely.
-
Provision new nodes from a fresh OS image with Kubernetes pre-installed.
-
Managed by tools like kOps, kubeadm scripts, or cloud auto-scaling groups.
Pros: Very reliable, ensures clean state
Cons: Requires infrastructure as code and automation
4. Step-by-Step: Operating System Upgrades in Kubernetes Clusters
Operating System Upgrades in Kubernetes Clusters using a rolling node replacement strategy.
Step 1: Check Node Status
Ensure all nodes are Ready.
Step 2: Drain the Node
This moves workloads to other nodes while keeping critical daemonsets running.
Step 3: Upgrade the OS
sudo apt update && sudo apt upgrade -y
sudo reboot
sudo yum update -y
sudo reboot
Step 4: Verify After Reboot
Step 5: Uncordon the Node
The node can now schedule workloads again.
Step 6: Repeat for All Nodes
Upgrade nodes one at a time to avoid downtime.
5. Post-Upgrade Validation
After upgrading all nodes:
-
Check Cluster Health
-
Test Critical Workloads
Ensure applications are functioning as expected. -
Monitor Logs
Check for kubelet or container runtime errors:
6. Best Practices for Operating System Upgrades in Kubernetes Clusters
-
Schedule Maintenance Windows — Perform upgrades during low-traffic hours.
-
Backup etcd — Protect cluster state in case of failure.
-
Automate with Ansible/Terraform — Reduce manual steps and human error.
-
Test in Staging First — Validate upgrades in a non-production environment.
-
Update Container Runtime — Docker, containerd, or CRI-O should be updated alongside the OS.
-
Sync OS and Kubernetes Version Compatibility — Check Kubernetes version skew perform
7. Special Considerations for Managed Kubernetes
If you’re using GKE, EKS, or AKS:
-
The control plane OS upgrades are handled by the provider.
-
You only need to upgrade worker node pools — usually through the provider’s dashboard or CLI.
-
Cloud providers often offer node auto-upgrade options, but testing before enabling in production is recommended.
8. Common Pitfalls and How to Avoid Them
| Pitfall | Solution |
|---|---|
| Upgrading all nodes at once | Use rolling upgrades to keep workloads running |
| Forgetting to drain nodes | Always drain to avoid disrupting running pods |
| Ignoring kernel compatibility | Check required kernel version for Kubernetes |
| Skipping container runtime updates | Upgrade runtime alongside OS |
| No rollback plan | Have snapshots or VM images ready |
9. Final Thoughts
Operating System Upgrades in Kubernetes Clusters are not just about staying current — they are about ensuring security, stability, and compatibility for your workloads.
By adopting a planned approach, using rolling upgrades, and testing before production rollout, you can minimize downtime and risks.
Operating System Upgrades in Kubernetes Clusters regular part of your Kubernetes maintenance routine, just like cluster version upgrades, to keep your environment secure and reliable.
Learn more about click here